
12:43 Uhr EDT – Der erste Vortrag, der heute bei Hot Chips live gebloggt wird, stammt von Tesla, die ihre Rechen- und Redundanzlösung für ein vollständig selbstfahrendes Auto vorstellt. Wir gehen davon aus, dass dies ein Auto der Stufe 5 ist. Es wird also interessant sein, zu sehen, was erwähnt wird.
12:56 Uhr EDT – Wir fangen gleich an
13:00 Uhr EDT – Präsentiert von einem ehemaligen AMD-Architekten, der an Bulldozer und Zen gearbeitet hat
13:01 Uhr EDT – FSD = Fully Self Driving
13:01 Uhr EDT – Benötigte Custom Hardware um CNN sehr schnell laufen zu lassen

13:01 Uhr EDT – Level 5 ist ein hartes Ziel
13:01 Uhr EDT – 100 W waren ein Limit für den Computer
13:01 Uhr EDT – FSD musste in HW2.x-Fahrzeugen nachgerüstet werden
13:02 Uhr EDT – Die Kühlung in diesen Autos ist begrenzt
13:02 Uhr EDT – HW2.x war vor FSD
13:02 Uhr EDT – Betrachtet man den Markt, ist nichts geeignet, um die Leistungsanforderungen und Formfaktoranforderungen zu erfüllen
13:02 Uhr EDT – Tesla musste einen eigenen Chip entwickeln, um diese Ziele zu erreichen
13:03 Uhr EDT – Doppelredundante SoCs

13:03 Uhr EDT – Redundante Netzteile
13:03 Uhr EDT – Abwärtskompatibel
13:03 Uhr EDT – Überlappendes Kamerafeld mit redundanten Pfaden
13:03 Uhr EDT – Vier der Kameras sind blau, vier grün
13:03 Uhr EDT – Alle Informationen gehen an beide SoCs
13:04 Uhr EDT – Beide können alles unabhängig voneinander verarbeiten
13:04 Uhr EDT – Reichhaltige Sensorsuite

13:04 Uhr EDT – Kameras, Radar, GPUs, Karten, IMUs, Ultraschall, Rad-Ticks, Lenkwinkel
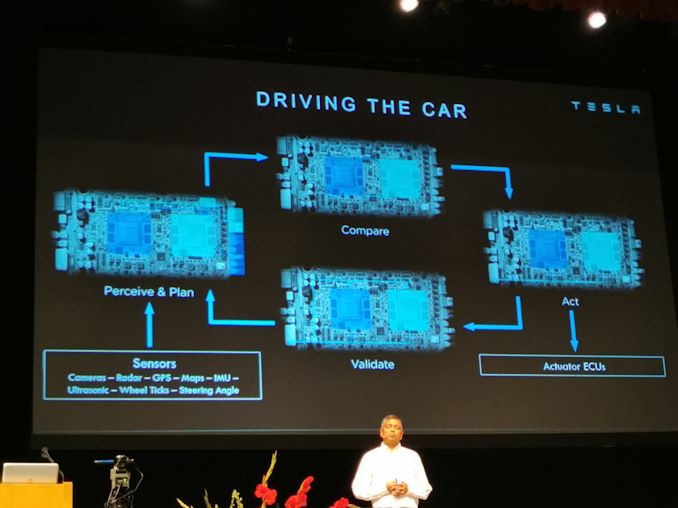
13:05 Uhr EDT – Zwei SoCs haben Pläne. Pläne werden verglichen, und wenn sie übereinstimmen, werden vom Master Maßnahmen ergriffen und vom Slave-SoC validiert und wiederholt

13:05 Uhr EDT – Wie viele TOPs für Tesla-Workloads waren 50 TOPs ein Mindestbarren
13:05 Uhr EDT – Hohe Auslastung für Losgröße eins (Video)
13:06 Uhr EDT – Endete mit Sub-40W / Chip. Klassenbester Wirkungsgrad für Rückschlüsse
13:06 Uhr EDT – Führende Latenzergebnisse. Schutz und Sicherheit bekommen spezialisierte Verarbeiter
13:06 Uhr EDT – Samsung 14FF

13:06 Uhr EDT – 260 mm2, 6b Transistoren
13:06 Uhr EDT – AECQ100
13:07 Uhr EDT – 12 A72-CPUs rechts, 1x GPU

13:07 Uhr EDT – Zwei Neural Network Accelerators, ein von Grund auf neu entwickeltes Design. Alles andere ist industriell geschützt

13:07 Uhr EDT – Zwei NNAs mit jeweils 96 x 96 MACs können 36,8 TOPs pro NNA ausführen
13:08 Uhr EDT – 32 MB SRAM pro Instanz, bandbreitenoptimiert
13:08 Uhr EDT – Viele Programme können in SRAMs gespeichert sein
13:08 Uhr EDT – Einfaches Programmiermodell
13:08 Uhr EDT – Für 2 GHz + gebaut
13:08 Uhr EDT – 72 TOPs für den gesamten SoC bei 2 GHz
13:08 Uhr EDT – 14 Monate von Arch bis Tape
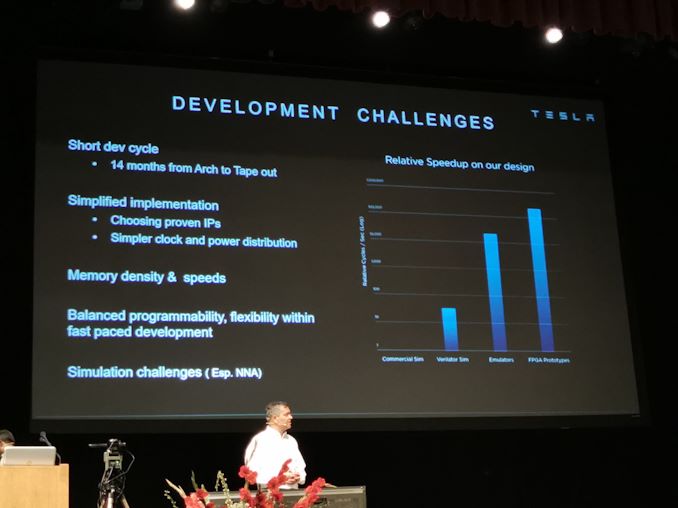
13:08 Uhr EDT – Erster Siliziumerfolg
13:08 Uhr EDT – Einige kalkulierte Risiken in Bezug auf das Design eingegangen
13:09 Uhr EDT – Simulationsaufgaben
13:09 Uhr EDT – Musste es richtig machen
13:09 Uhr EDT – Verwendeter Verilator, 50x schneller als kommerzielle Simulatoren
13:10 Uhr EDT – NNA Design Motivation. Lösen Sie ein faltungsbedingtes neuronales Netzwerk

13:10 Uhr EDT – 99,7% der Vorgänge sind MACs
13:10 Uhr EDT – Durch die Beschleunigung der MACs wird das Qualtieren / Poolen empfindlicher
13:11 Uhr EDT – Dedizierte Quantisierung und Zusammenfassung von Hardware, um die Dinge zu beschleunigen
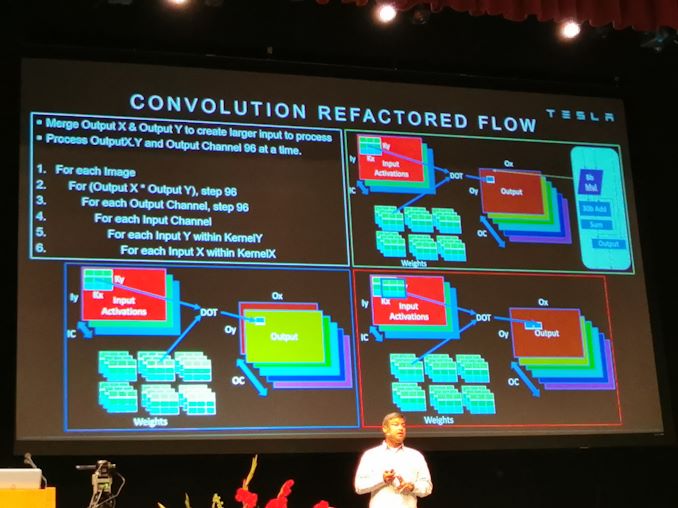
13:13 Uhr EDT – 8-Bit-MULs mit 30-Bit-ADDs
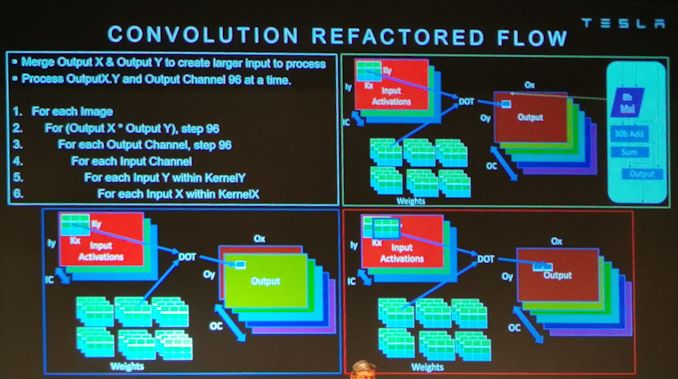
13:15 Uhr EDT – Über die Rutsche gehen. Grund MatMul Zeug

13:20 Uhr EDT – Kontrollfluss ist extrem wichtig für Perfektion und Leistung
13:20 Uhr EDT – Die meiste Energie wird für das Verschieben von Anweisungen und Daten aufgewendet
13:21 Uhr EDT – FSD eliminiert DRAM-Lese- / Schreibvorgänge
13:21 Uhr EDT – SRAM-Lesevorgänge minimieren
13:21 Uhr EDT – Optimierte MAC-Schaltleistung
13:21 Uhr EDT – Single Clock Domain
13:21 Uhr EDT – DVFS-Strom- / Taktverteilung
13:22 Uhr EDT – Zum Schluss, wenn Sie mit einer Ebene fertig sind, kann sie zerstört und nicht beibehalten werden
13:22 Uhr EDT – Instruction Set – Hier sind alle Operationen
13:23 Uhr EDT – Eingeschränkte OoO-Unterstützung
13:24 Uhr EDT – Befehle sind 32B bis 256B (256B = Faltung in einem Befehl)
13:24 Uhr EDT – NNA-Mikroarchitektur
13:25 Uhr EDT – 32 MB SRAM mit einem Port pro Bank
13:25 Uhr EDT – 256B Lese-BW, 128B Schreib-BW
13:25 Uhr EDT – 1 TB / s SW im SRAM
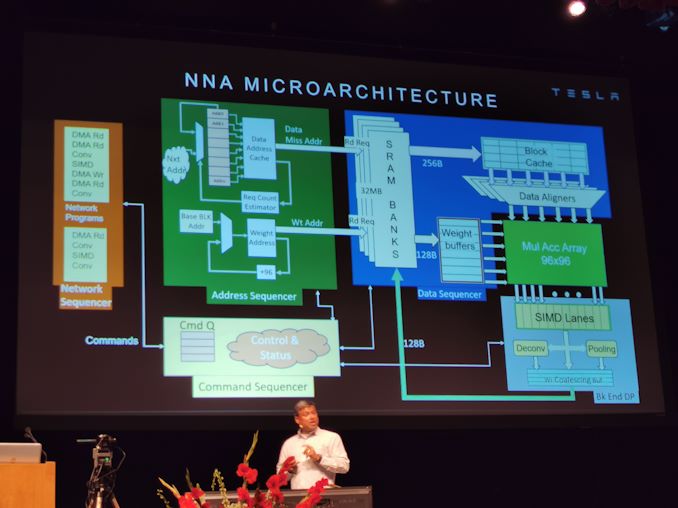

13:27 Uhr EDT – Programmierbare SIMD-Einheit mit 3 Zyklen
13:28 Uhr EDT – FP16- und INT-Datentypen
13:28 Uhr EDT – Predication-Unterstützung für alle Anweisungen

13:29 Uhr EDT – Max Pooling und durchschnittliches Pooling
13:29 Uhr EDT – Benutzerdefinierte Pooling-Hardware erforderlich
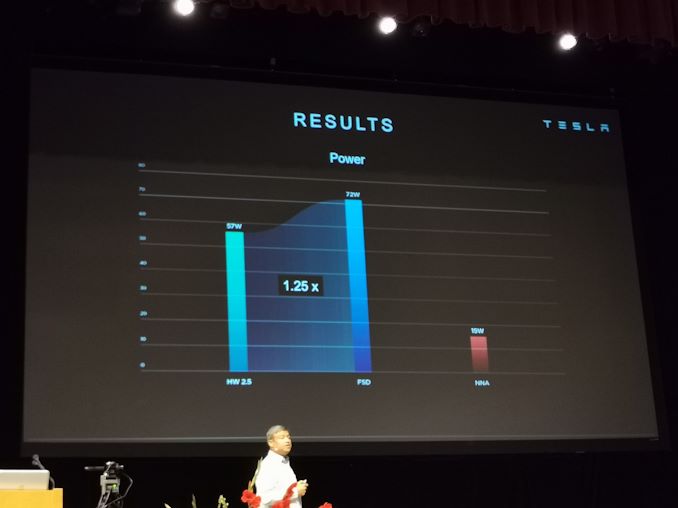
13:30 Uhr EDT – 2,5-fache Leistung über HW2.5-Plattform für 1,25-fache Leistung
13:30 Uhr EDT – Modulkosten um 20% gesenkt

13:31 Uhr EDT – Fragen und Antworten
13:31 Uhr EDT – F: Dual redundante SoCs. Einblick in den doppelten Aspekt? Teilen Sie die Last? A: Die Software-Leute haben die Flexibilität, es so oder so zu verwenden. Wir haben in erster Linie auf Sicherheit ausgelegt.
13:32 Uhr EDT – F: 2 Instanzen der Convolution Engine. Warum 2? A: Ziel der Bandbreite, die mit 96×96 x2 erreicht werden soll. Sweet Spot für physisches Design, Fläche, physisches Design.
13:32 Uhr EDT – F: 37 TOPs? A: INT8
13:33 Uhr EDT – Q: Benutzerdefiniertes Modell oder öffentlich? A: Benutzerdefiniert
13:35 Uhr EDT – F: Warum eher SoC als PCIe-Karte? A: Die Automobilindustrie muss einen intensiven Lebenszyklus durchlaufen. PCIe-Karte würde nicht funktionieren.
13:35 Uhr EDT – F: Protokollierung? A: Ja
13:36 Uhr EDT – F: Was ist, wenn die beiden SoCs nicht übereinstimmen? A: Wir haben eine hohe Framerate. Ein fallengelassener Frame beeinflusst die Perfektion jedoch nicht.
13:37 Uhr EDT – F: Rohe Tops? A: Ja
13:38 Uhr EDT – Q: Abkühlen? A: Hängt von der Fahrzeugplattform ab. Luft oder Wasser. Für diese Plattform war jedoch die Reduzierung der Leistung der Schlüssel
13:38 Uhr EDT – Das ist ein Wrap. Pause, als nächstes kommt NVIDIA Multi-Chip
13:38 Uhr EDT -.
